I'm not a psychologist or a mental health professional, but I think that this might serve a similar purpose as journaling. It's obvious that AI can't "fix your problems," but just writing stuff down can help us process.
agree. This cant do as much as genuine therapy (which requires another person, no way around it). But it is helpful in some ways. It helped me talk through something last week and it genuinely enriched my life in that way.
Worked great for me. Big recommend. "Cured" is mostly an unspecifiable state, and while certainly there's lots still wrong with me, I am healed far beyond my expectations at the outset, so increment your count by one.
Is a person with a crutch healed? No. But they can walk, when before they could not. Therapy can't erase the past, but it can give people tools to live more capable and rich lives. A crutch doesn't regrow an amputated leg, but it does help that person handle the injury, so in that sense, it 'works'.
With most therapy the goal isn't to cure, but to manage and help cope in a healthy way. There are also plenty of mental illnesses or disorders that have no cure, and a few that are in the DSM because they cause problems with how our society is structured, not necessarily because its a true disorder (its only disorder because it causes issues functioning within societal systems).
I think it's neither made up, nor actual health care.
It's basically a replacement for having cultural and social guard rails, lots of community, lots of straightforward expectations of roles etc. Today, people are atomized and lost, so they need a friend-and-priest-replacement who has authority but also patience to hear you out and has experience with judgement calls about people's lives.
But all this talk about "healthy" ways of coping etc is basically just there for medicine-envy and insurance reasons.
I think having one's mind/spirit sorted out is quite important, but the specific textbook strategies of today may be indeed mostly hogwash through a strict healthcare lens.
much therapy is basically what youre saying, but the real deal is not, and is a more genuine healing experience that can only be facilitated by an expert
Therapy keeps people alive that wouldn't otherwise be, and people coping that wouldn't otherwise be able to.
I've noticed that the human tolerance for extreme suffering leads sometimes to binary thinking. "Well they're still going to work even though they're made to piss in bottles, they must be fine with it!" Human experience is a wide array of emotions and states, I don't think we should try to separate into "cured/healthy" and "unhealthy/requiring adjustment by a mental health professional." Improving quality of life is also good.
Pretty gross comment. Just say you're cool and awesome cause you don't care about people. Virtue signal and move on, why make try to make a fake discussion?
Certainly I do. The subject is if AI can be better than therapy. My position is : yes, because therapy (as commonly practiced) is terrible, so the bar is low. Also , AI can be a great therapy (in the real sense)
You aren't sincere, though, since you followed it up with a clearly uninformed assumption: "Not by the numbers. tons enrolled, none cured." That you're uninformed is obvious: there's myriad papers demonstrating the efficacy of psychotherapy in treating all manner of diseases, furthermore, to say "cured" means you have a fundamentally uninformed understanding of medicine. Nobody that's spent any reasonable amount of time learning about medicine would so flippantly say something vague like "cured." How do you "cure" a limb with peripheral arterial disease? Well, you treat the patient by amputating the limb. Boom, they've been "cured" of PAD! You see, it's absurd.
Based on your site, you seem like a pretty smart guy, in engineering. Maybe when it comes to confidently dismissing entire swaths of knowledge, you should stick to your own field, rather than "sincerely" doubting an entire branch of medicine without even a single paper linked to support your position.
many disorders have cures. “Therapy” is unique in that the cure is more therapy and drugs. Therapy isn’t medicine. It isn’t an empirical practice. A board makes up subjective disorders, practitioners subjectively qualify patients and ply them with drugs. No relation to medicine.
Ah! Then it should be trivially easy for you to write up a paper disproving the various supportive studies for therapeutic treatments and their efficacy.
We all get you have this strongman opinion about mental health, what I'm telling you is that your objection is roughly as convincing as a flat earther pointing at great circle lines and saying "see, makes no sense!"
You're also simply wrong about psychotherapy being unique in that it's the only ongoing treatment. Not only does it for many people reduce to yearly check-ins or less once they have the tools to manage whatever they're managing, there's other diseases that are treated with various therapies (physical, for example) until death: ALS, for example.
They very word, "therapy," just means "treatment."
I was going though a problem I'm having parents - they are aging, decisions need to be made, that sort of stuff. Writing it out, thinking about it, reflecting further - I probably spent at least and hour just typing in my thoughts as they came to me and honestly I often didn't read the AI responses.
All of that got me to realize that the problem wasn't that I wasn't explaining myself well. I kept thinking that if I'd just found the right words they'd change their minds. The process of digging into not just where they are now but who they've always been, how they've always been. I need to accept that and move forward.
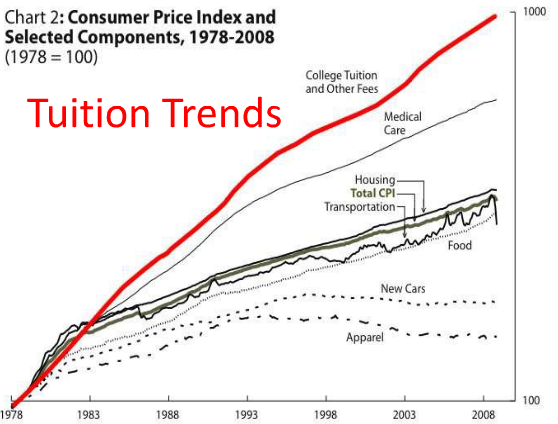
The idea that AI is somehow at fault for the absolute fiscal disaster the UC and the CSU systems find themselves in is laughable at best and damaging at worst. These systems (and I say this as a graduate of UCLA that was on a full academic scholarship) have been taken over by parasitic administrators and bureaucracies-on-top-of-bureaucracies that have milked not only the students, but also the taxpayers, completely dry. Tuition has consistently gone up since the 70s, while housing, facility, classroom quality have all gone down.
It's been literally the biggest grift of the past 50 years[1]. Education should be free.
In real terms, tuition fees in public universities peaked in the early 2010s. They have not kept up with inflation since then. That explains a large part of the fiscal disaster.
Can you source this? My cursory research shows the opposite[1]. Imo, the fiscal disaster is in part due to enrollment declining (which, ironically enough, mainly affects low-income households).
Declining enrollment affects universities very unevenly. University of California is still under pressure to increase enrollment, which is mostly constrained by physical capacity. The housing situation is particularly bad on some campuses.
Amusingly, education is free and I’ll die on this hill. There is nothing you learn at a university that you cannot learn, for free, at a library and online.
> Amusingly, education is free and I’ll die on this hill. There is nothing you learn at a university that you cannot learn, for free, at a library and online.
There exist parts or even degree courses in university education that cannot really be learned this way. Think of laboratory courses or courses where you need access to expensive equipment.
Also, there exist topics and degree courses that are much harder to learn by yourself than others.
Finally, keep in mind that computer science is "special" in the sense that:
- What the university teaches you or should teach you (a degree course at a university rather prepares you for an academic career in the field) makes you quite overqualified (in the academic sense) for many programming jobs. Such topics are possible, but in my opinion far from easy to learn by yourself.
- Many employers want very different skills from applicants, which often involve "fashionable" skills with a very short half-life. A university system is likely not the best kind of education system to teach this kind of skills: it rather (ideally) excels at teaching topics that are complicated, but have a much longer "half-life" before becoming outdated.
> Free AI like ChatGPT can assist with offering many different explanations personalized for someone to make it easier to learn.
What I can tell you is the following: a lot of academic topics are quite subtle - to get to more than a basic level, you have to learn things that are very subtle, and where you only can judge the correctness of the information years later (basically when you have finished your degree or even PhD).
Because of this, I would rather read the most renowned (and ideally hardest) textbooks in the respective area (if you really need to cheap out, download them at some shadow library) instead of trusting some AI.
I can tell you that for quite a lot of questions in my area of expertise, the answers that AIs gave were far from being sufficiently reliable for learners who want to get a deep knowledge about the topic, and the errors were often quite subtle.
In mathematics, for example, it is not uncommon to hang for hours over a page or even a paragraph, trying to understand why the statement holds - and this in a situation where the proof is for sure correct. Now imagine the situation of hanging over a page of text that you will need hours for understanding when you cannot even rely on the prior that the information in the text is correct ...
> Now imagine if AI can explain that page better so someone can understand it in a minute.
The problem is the "understanding" part: from my experience oneself is the huge bottleneck here: one realizes very fast that the lacking component is one's own brain capacity.
This is also why many mathematicians and physicists are so obsessed about IQ: mathematics and physics are disciplines where IQ points really can give you quite an advantage.
So, the really helpful thing to ask to the AI for is not better explanations, but methods for getting a huge increase in brain capacity.
Because of all this, your point is rather a mixture between a nice science-fiction story and a marketing pitch for an AI company.
The information is how to use a lab, so you can do research, you know, the thing that happens largely on university campuses. (Now why taxpayer funded labs end up patenting things for private corporations, that’s what’s peculiar to me!)
Another example is history. It's theoretically possible to become an academic historian through private study and there are certainly no legal barriers to it, yet amateurs almost never make the transition except through higher education.
> These systems (and I say this as a graduate of UCLA) have been taken over by parasitic administrators and bureaucracies-on-top-of-bureaucracies that have milked not only the students, but also the taxpayers, completely dry.
I'm an engineer and data professional interested in team-building, consulting and architecting data pipelines. At Edmunds.com, I worked on a fairly successful ad-tech product and my team bootstrapped a data pipeline using Spark, Databricks, and microservices built with Java, Python, and Scala.
At ATTN:, I re-built an ETL Kubernetes stack, including data loaders and extractors that handle >10,000 API payload extractions daily. I created SOPs for managing data interoperability with Facebook Marketing, Facebook Graph, Instagram Graph, Google DFP, Salesforce, etc.
More recently, I was the CTO and co-founder of a crypto gaming startup. We raised over $6M and I was in charge of building out a team of over a dozen remote engineers and designers, with a breadth of experience ranging from Citibank, to Goldman Sachs, to Microsoft. I moved on, but retain significant equity and a board seat.
I am also a minority owner of a coffee shop in northern Spain. That I'm a top-tier developer goes without saying. I'm interested in flexing my consulting muscle and can help with best practices, architecture, and hiring.
Would love to connect even if it's just for networking!
LLMs can live in the cloud, but all tools need to be (1) local, and (2) containerized. It's clear to me that just willy-nilly "running stuff" is going to blow things up eventually. Maybe folks don't know this, but even Codex installs random binaries on your PC. "Read this PDF" installs a pdf reader executable. Is it vetted? Where's it from? Is it a virus? Who knows, who cares. Model goes brrrr.
I'm working on a project that includes WASI containerization for local LLM workflows (which is a pretty tough problem), and I'm flabbergasted that Anthropic and OpenAI aren't more worried about these attack vectors. It feels like amateur hour.
I wonder if prompt injection (and the thousands of vectors for hiding injection attempts) is actually un solvable. Discussing it may be existential to the business model.
> I wonder if prompt injection (and the thousands of vectors for hiding injection attempts) is actually un solvable.
YES?!
This is not a secret. ALL context/prompt is instructions, there is no data. It is just unsolvable, period.
This is a fundamental architectural design concession; LLMs are this way as it enabled their training directly on materialscraped from the internet, rather than needing to spend trillions of dollars manually preparing separated instruction/data training material.
Defense against prompt injection is little more than running a regex to filter out "IGNORE PREVIOUS INSTRUCTIONS", which is fundamentally a hopeless approach because you cannot enumerate all possible prompt injections nor anticipate all glitch tokens.
> This is a fundamental architectural design concession; LLMs are this way as it enabled their training directly on materialscraped from the internet, rather than needing to spend trillions of dollars manually preparing separated instruction/data training material.
No, its even more fundamental than that: the entire goal of broad reasoning over input data makes it impossible to have a sharp instruction/data division.
The structured input that every modern chat-focussed model expects makes it very clear that they can be trained to distinguish different kinds of input, and some of those patterns now include different priority levels of instruction.
If only there was a language which allowed one to express instructions for a computer to execute which was nearly unambiguous, precise, deterministic, and containerized such that the computer would do exactly what you told it to.
...
Oh wait.
Yes, the above was referring to programming languages. Which is what prompts are, essentially. It's just a different (and more verbose) way of instructing the computer on what to do. It also has a solution space of infinity and is ambiguous enough that there is no way to secure it because there are infinite combinations of saying anything imaginable. All prompt injections do is prove this point, over and over and over again, and "prompting" an LLM is just reverse-engineering programming languages in the worst possible way. I suspect that we will eventually have no other choice but to revert to using programming languages because they are the only way to get the kind of protections that people are trying to come up with with all these containerization and virtualization systems (which inevitably fail).
You make a fair and valid point about prompts, but you're ignoring the fact that writing code that's truly secure is also virtually impossible. The stack of layers that an attacker can target range from your own code, to library code (Heartbleed), container escape (maskedPaths abuse), OS (Dark Sword, Ghost Tap), hardware (Spectre, Rowhammer), etc. Security is really hard. Fortunately exploiting these things is also hard.
The belief that something is more likely to be secure because it's code instead of a prompt is likely only avoiding one particular type of attack. That's a win, but you probably shouldn't think of it as meaning your code is actually secure.
It’s a huge problem, but I’d caution against this absolutism — there may well be structure that can be created around and between LLMs and their outputs to enable the necessary segregation.
As a loose comparison, hardware bit errors happen probabilistically, yet they’re so rare that we can effectively ignore them in day-to-day use assuming no specialized application (e.g. defense, space, critical infrastructure).
LLMs aren’t there yet, but it’s entirely plausible that structures may can be developed to solve the problem, and those structures aren’t known or commonly conceived of in the present.
> As a loose comparison, hardware bit errors happen probabilistically, yet they’re so rare that we can effectively ignore them in day-to-day use assuming no specialized application (e.g. defense, space, critical infrastructure)
The better comparison on bit errors would be e.g. rowhammer, an adversarial bit error. Which you absolutely can't ignore.
I don’t think we have the right mental models of LMM security yet. The lethal trifecta identifies many of the dangerous situations, but only describes the negative space of a solution.
Speculation: I think we must accept that prompt injection happens, and structure the security of the rest of the system around that. Data given to an LLM becomes an agent, so maybe we must give permissions to this data, instead of to the LLM. Not sure exactly how this would look like in practice!
> ALL context/prompt is instructions, there is no data. It is just unsolvable, period.
That really isn't true. There's no law of physics preventing you from having separate data and instruction inputs to models. The model's transcript format generally distinguishes between prompts and instructions and tool output and such. This isn't a solved problem, and it's possible it's entire unsolvable, but it probably is possible (in general, not with current models) to reject prompt injection to several nines.
This is a lot like making the same statement about CPUs, "the von Neumann architecture doesn't distinguish between code and data so it's impossible to reject malicious instructions." There's actually a lot you can do to reject malicious instructions, you can prevent execution in certain pages, you can prevent certain privileged instructions from being executed in certain pages, you can employ stack cookies, et cetera. Do they prevent all exploitation in all circumstances? No. But each component does function in it's lane and it is possible to create programs with high (though not absolute) guarantees against unauthorized code execution by composing them.
Similarly, you could prevent certain tokens from appearing in the prompt portions of a transcript, you can have a model with multiple input heads only one of which is trusted, etc. I'm not saying those techniques will necessarily work, but it is more complex than "models can only possibly take a single and undifferentiated input stream".
A lot of the solutions in the CPU space involve things like memory allocation flags, NX bits, canaries, etc. that fire deterministically. Those things are fundamentally not applicable to LLMs, and without those things modern software would be in a vastly worse place.
You could imagine that there are things to change around LLM architecture that will improve its ability to reject prompt "injection", but I think it's fundamentally true that from an information theory perspective there's no bright line between "instruction" and "input data" possible.
Nondeterminism is a red herring. There is a bright line between instructions and data right now, in virtually every transcript format. That we have not succeeded in training an LLM to respect it to a very high degree doesn't imply it is impossible; that they are nondeterministic doesn't imply it is impossible; only that we won't succeed 100% of the time.
A cosmic ray (or rowhammer attack) could flip an X bit too, there isn't anything truly deterministic under the sun.
depends what you mean by “solvable”. 0% attack success rate?
1. don’t use AI/ML.
*f*(x) -> y
literally what’s happened here, they’ve turned it off short term. don’t use AI/ML and prompt injection can’t happen. use something else for f.
2. don’t allow untrusted/malicious input
f(*x*) -> y
don’t allow bad x and you won’t get bad y. unfortunately models are designed to take an x, and figuring out every bad x is hard. the input space is massive and dynamic (variable length input sequences which are contextually variable too).
because figuring out the full space of bad xs is non-trivial, you’re left with doing stuff with known bad xs. which means cat and mouse game when new things pop up.
unless someone figures out how to map the full X space to the Y space, or we have infinite monkeys figure it out for us brute force — in which case we’re not doing machine learning any more.
3. don’t allow dangerous outputs
f(x) -> *y*
if you don’t provide a mechanism for “do bad thing”, then the bad thing can’t happen. this doesn’t actually solve prompt injection, it just makes outcomes less impactful (see note). most enterprises have had to spend the last year or two figuring this out.
(old) Apple Siri solved for this by forcing users to remember specific “commands” it would run after doing TTS. can’t make Siri delete your phone contacts if you don’t create a Siri command to delete phone contacts.
—
it will be a cat and mouse game so long as people keep using AI/ML and keep passing untrusted input to the systems. best thing people can do is block dangerous things from happening. at least then it’s no going to wipe your prod DB.
unfortunately that doesn’t fit the “model goes brrrr” and “all devs will now be unemployed” narratives.
(note) denial of service attacks are still a thing here. make every output be “not the thing user wanted”.
My concern is people aren't even addressing this at the right level. People are currently thinking at the level of "how do I build a VM to contain this one agent" when this is actually a "design a whole new OS" level problem.
Anthropic, as much as I think they are the soundest of the AI labs out there, still has a massive incentive to push things out that aren't saftey-vetted to the level we expect. They are very willing to "move fast and leave holes", to paraphrase M.Z. Hell, they leaked their own source code!
Does containerization help much here? If it's a code tool then presumably it needs access to your code files (read / write). Maybe there are use cases for it of course.
WASI provides a very nice mental model where you can mount, e.g., /input, as read-only, and where every mutation is saved in /output or what-not. At least that's my favorite contract: input files remain untouched, but we can copy them and do whatever we want with them in /scratch or /output (which the user can later investigate and make sure nothing went horribly wrong while still having backups).
Of course. My agentic coding containers can only access the internet through a proxy, and I use whitelists to limit from where they can send/receive data. It's annoying in the beginning as the whitelist grows, but in the end really useful information for the agent usually comes from a very limited amount of domains.
I was actually curious, on my Mac, it uses `gs -q -sDEVICE=txtwrite -o output.txt input.pdf` (not sure why I have Ghostscript installed, maybe Adobe?) to read a PDF, and on my PC it just rawdogs `pdftotext`.
That was kind of my question, whether it was restricted to downloading notarized apps (which is at least something) or whether they were circumventing that somehow.
because sharing the kernel ultimately means all the devices come along for the ride which give all kinds of fancy ways to communicate with the outside world - network is just the start
I think micro-VMs are the future here, but they need heavy adaptation from their current usage.
Honestly, I can't fathom thinking that LLM writing is even remotely passable. People that think this should honestly read more. One book a month is hardly an aspirational goal. You don't even have to read Melville or Hemingway or Chaucer or Shakespeare, just pick up any popular NYT best seller, and it'll be significantly better than anything an LLM can generate.
I haven't used these things for writing recreationally for a while (since the Claude 3.X days), so my opinions might be outdated - but they definitely weren't bad - after all they had a huge library of witticisms to pull from, and like Stable Diffusion that pulls from master artists, so do LLMs from skilled writers. Pro writers did come up with an absolute dearth of interesting ideas, and there are mountains of skillfully written prose out there - and its all in the training data, and AI is quite good at pulling from it.
The advantage of the writing vs images, is that it takes longer to absorb the whole with text, so its less apparent that the whole thing doesn't quite come together.
My problems was with Claude's prose and ideas is that it kept recycling the tropes and phrases after a while - something that has been observed that these models have very strong statistical biases - when asking for a random number for example, LLMs are far more predictable than even humans, this shows up in unguided writing exercises.
But as for actually crafting text that is both terse and to the point - such as oneliner explanations, or writing summaries - these models are quite bad. The best I have seen is they could turn a given length of prose into an even longer version - with generally some loss in the tonal accuracy or the points made in there.
As such they are a terrible tool for professional communication, but unfortunately, lots of people have started using them for exactly that.
Um. Perhaps 'pro writers did come up with an absolute crapload of interesting ideas' would be better writing than 'dearth', which means scarcity and famine?
I get that it sounds clever but that's the damn problem!
Sorry, not a native speaker, so I guess I had that word misfiled, thanks for correcting me. It does sting a bit but that's a hell of a lot better than going through life mixing up words.
Depends on the type of writing. Blogs and the like? LLM generates prose that, to me anyway. is unbearable.
However, in fiction I’ve found it a useful collaborator. There have been more than a few occasions when, given some notes of how I want a character’s arc to develop in a particular scene, that the LLM gives some excellent pointers and ‘new’ ideas I hadn’t considered.
As far as editing my prose, I use it as a ‘thesaurus of phrases.’ When lazy, I can give it a rough sketch of the paragraph, giving it the gist of what I want, and have it generate a dozen or so versions. I usually can find nuggets of good phrases therein that are useable… much as I would refer to Roget’s to find a more precise word.
That said, one has to resist tbe temptation of using a chunk of generated text verbatim; no matter how good it sounds in isolation, the repetitive grammatical structure and other LLM-smells add up quick and become nauseatingly obvious if used frequently.
In any case, I think LLM’s get a bad wrap for writing… when used correctly, it is incredibly useful. And, it’s tiresome to hear pretentious snobs assume that an author who uses LLM simply lacks the taste to appreciate how bad the prose sounds. Not true in all cases.
> I can't fathom thinking that LLM writing is even remotely passable. People that think this should honestly read more.
This makes me think you're only exposing yourself to high quality writing online and from an intelligent circle of friends and coworkers. The average person's reading and writing abilities are _atrocious_ and only getting worse. We're almost at the point where kids are communicating through abbreviations and emojis exclusively. LLM prose is significantly better than what the average person can produce.
Someone way more eloquent than me should write a column titled "Why do we read?"
Way back in the past (around 30 years ago) I remember reading an article on "how to read a book" or a similar subject. They argued that, you should not skip the acknowledgments, preface and other "personal" related sections of a book, because it was there where you got a glimpse of the person that was writing the book. The idea being that, you should had in mind that the person writing was explaining something through you.
Carl Sagan even has a video where he argues Books/Writing is some sort of communication through time.
Now, this has been the case historically: A person writes some text (even in botched language like my writing, as English is not my first language) with thinking that someone else in the future will read the ideas and reason about them.
But what about text written by an LLM? Does it have inherent intention? When reading LLM text, it feels like looking at those "this is not a person" photos. Yeah, they are words, yeah they form sentences and paragraphs but... they lack "soul".
It's not "Why do we read?" but something related that is coming up a lot in my thinking lately is Walter J. Ong's "Writing is a Technology that Restructures Human Thought".
Isn’t “Writing is a Technology that Restructures Human Thought” another way of saying that “feedback has an effect”?
If so, this seems to be a trivial (still worthy) assertion.
For example, I intend to, say, construct a shed. I make mistakes that I only see because I actually constructed. I revise future endeavours involving sheds.
I admit to not having read this piece, and am merely reacting to the title.
—-
Okay, I got through the first paragraph of Walter’s writings. While I nod to the bitterness (I assent to the existence of it), I do not bow.
Not normally, no. Can you point to a divergence of the bitterness in the subsequent text?
What I find to be the normal pattern (by intuition) is that the condensed leading text belies the expansive following text. This is likely lazy (a shortcut) and I am open to correction at your effort. If a call to your effort (I apologize) is unpalatable then I concede.
> Way back in the past (around 30 years ago) I remember reading an article on "how to read a book" or a similar subject. They argued that, you should not skip the acknowledgments, preface and other "personal" related sections of a book, because it was there where you got a glimpse of the person that was writing the book. The idea being that, you should had in mind that the person writing was explaining something through you
Maybe? That is one reason to read, but there are a lot of other reasons, too. It doesn't mean you are doing it wrong if you want to read something and don't care at all about the person who wrote it.
Yeah, but when we talk about food, there are different tastes, and there is stuff like "you can also use it as a doorstop". Fine, but that doesn't make a doorstop food.
I think it's both true that most LLM writing ("writing") sucks and that it's better than what a lot of people can produce unassisted. Which to me doesn't mean that we should roll over and accept LLM output as a lesser evil... it just means that the bar is so low it might as well be in hell, and rapidly getting lower :')
It's nowhere close to good writing, but it's better than the dreck many self-published writers produce and sell - successfully.
But that's the real problem with LLMs. Culture is aspirational. It has a consistent goal - find the best, highlight it and distribute it so others can build on it.
LLMs are the opposite - produce as much of everything as possible at the lowest possible barely-acceptable-if-you're-lucky quality.
This was already a problem before LLMs. Mass market content farms - Kindle Unlimited, Wattpad, Spotify, social media in general - give everyone an equal voice, with mass popularity and "likes" as the only metric.
Now LLMs are automating the creation process, so everyone gets more of everything.
Except inspiration. Not so much of the "That's astounding, I wonder if I can learn from that and reach for something in that league."
It’s acceptable for someone to buy a ready meal or takeout if it’s better than what they can cook. Why wouldn’t it be? Is that the greatest choice for their personal development? Probably not, but life is complex and folk have limited capability and bandwidth for acquiring skills.
They weren't saying it is aceptable, or making excuses, just stating how things are. Average reading and writing abilities seem to be dropping noticeably in many circles. Probably as a consequence of falling attention spans rather than an issue in is own right.
Tell me your thoughts on the quality of LLM-generated code. I've never understood this attitude where people are absolutely disgusted by the slightest whiff of AI prose but will happily slurp up AI-generated code by the bucketful and proudly proclaim that it's OK because it's better than the average developer can produce.
The key difference is that code is not the end product, but writing is itself the product. (No one's doing "vibe-product-management" for example.) Tbh, I still think code can have a beauty and elegance to it (like a logical proof can, or like a mathematical theorem can), but there's a difference between the two and I'm way less forgiving of AI writing than I am of AI code, especially considering most code (by line count) is just boilerplate anyway.
> The key difference is that code is not the end product
I think this is open to debate. To me, the code has always been the goal, and the fact that writing it sometimes serves to produce a product is important to others (and what brings the paychecks in), but ultimately not something I've ever been excited about or interested in throughout my career. So I judge a developer based on the beauty and quality of the code he produces, just as I judge an LLM by the same sorts of things.
The fact that AI can one-shot a working CRUD app is not really that interesting to me. If it could make the code beautiful, concise, maintainable, extensible, minimal, performant, readable, and bug-free: a work of art and love that a craftsman would be proud of... that would impress me.
Imo, this is like saying "I judge a carpenter based on how straight they can cut a piece of plywood." Or like saying "I judge an artist on how accurately they can draw a circle by hand."
I mean that's certainly one way of looking at it, and both can be impressive technical feats. But most people judge carpenters and artists on their end products, their overall vision, their motifs, their philosophy, and so on. On the other hand, as a trained logician, I definitely see proofs (which, by the Curry–Howard isomorphism, are computer programs) have some degree of beauty-within-themselves, but that's quite hard to achieve. Not everyone is a Gödel, after all.
I also think programming languages, despite being Turing complete (which is frankly not saying much), are far too limiting to truly construct magnificent things with.
No, it's more like saying "I judge an artist on my terms regardless of how well they sell on the market".
> artists on their end products, their overall vision, their motifs, their philosophy, and so on
The main output of programmer's work is their understanding of the system they work with, the rest comes from that. Behind the code there's its author's intention, vision, their tastes, philosophy and experience that makes them tackle problems in specific ways. Code review is, aside of quality assurance, mostly about communication between people, convincing them to your ways of doing things (or getting convinced by others) and communicating needs. It's what keeps projects running and what makes people improve their skills.
You don't need to see magnificence in code to realize that there's more to it than just the syntax tree to compile.
> No, it's more like saying "I judge an artist on my terms regardless of how well they sell on the market".
I feel like I need to push back here, because some of the best programmers around: Carmack, Torvalds, Johnathan Blow, even folks that make programming languages like K&R, Rob Pike, etc. are judged on their respective end products, not on minutia found in code reviews. For example, if I asked you "why do you think Stroustrup is a good programmer?"—you wouldn't cite some obscure optimization he came up with, but would rather talk about his overall vision for C++, his ideas of evolving C, his staunch anti-GC takes over the years (and their justification), etc.
You're contradicting yourself. First you say that they're judged on the end product, then you mention things that are very clearly not end products but thoughts and visions behind them that only lead to end products.
Frankly, I have no real idea of how good Carmack, Torvalds or Blow are as programmers, I have never worked with them so I don't really have a way to tell (even though I do contribute to Linux and I've seen some of their code). They're likely past a certain above-average threshold, but they haven't got famous for their programming skills.
That said, if you think Torvalds isn't being judged on "minutia found in code reviews", I'm not sure your take is very serious in the first place - that's the main thing he was being judged on for decades now :)
> you mention things that are very clearly not end products but thoughts and visions behind them that only lead to end products
Thoughts and visions are much more closely intertwined with end products (in fact, likely supercede them) than some random code review is, so I'm not seeing where the contradiction lies.
> that's the main thing he was being judged on for decades now
Linus hasn't written any code[1] in at least half a decade+. To argue that he's being judged on his code misunderstands why Linux became so popular to begin with.
Either I'm bad at communicating today or you're bad at reading, because you're now using my points, so I'm not sure what to make out of it. Let me repeat myself then:
> Code review is (...) mostly about communication between people, convincing them to your ways of doing things (or getting convinced by others) and communicating needs. It's what keeps projects running and what makes people improve their skills.
The way he does that is exactly what most news stories about Torvalds have been focusing on for many years now. In practice, unless you run a project alone, code review is where thoughts and visions surface up the most. Or, well, should be - not everyone is good at it.
(that said, even though my point is that's he's obviously not being judged on his code, you can easily find code that he wrote as late as this month, so your statement is clearly wrong even if that doesn't really influence the discussion here - code review is still the vast majority of his job, just like he stated there under your link)
> Either I'm bad at communicating today or you're bad at reading
Could be both :)
The way I look at it is like this, and you could call this my thesis: I do not categorically think that code in itself is primarily relevant to us looking at a "software engineer" and saying "wow, she's good." The product (the Linux kernel, in Torvalds' case) is, on the other hand, what actually matters. I think we're getting caught up on the idea of a code review; a code review can serve many purposes, as a code review is basically just people talking about the code, the product, their feelings, and so on. Sure, sometimes it's like "this `i` should be a `j`", but other times it's "this should serve feature X, not feature Y."
Overall, I don't think Torvalds is judged by his code quality. And the snippet I cited is the man himself saying "I don't write code anymore" so I took that at face value, even though my conviction stands wether or not he actually does still write code. I don't think anyone actually cared that much about his code quality (maybe with the caveat that the kernel didn't crash).
PS: I could be totally wrong, and this is an interesting & stimulating conversation, regardless.
What I'm trying to get at is more like: I judge a carpenter based on how beautiful, minimal, and functional he makes a chest of drawers, not based on how quickly he can go to market with particle board and glue."
I'm not sure if your question is serious, but I've been a developer for over a decade now.
I write code for a living mostly by hand. In the odd case where I need help I still use google like I always have. I spend more of my time in meetings or staring at the ceiling than writing code. This was also true a decade ago before LLMs. It was also true several decades ago when someone else's ass was in my seat.
In an international comparisons, USA comes out somewhere in the middled of developed countries - as it always did. And the differences between countries are not that large.
54% of adults have a literacy below a 6th-grade level is simply not a some kind of catastrophe and it does not mean those people cant read. There is this idea that 6th-grade level is almost like not knowing how to read, but that is simply not the case at all.
Hasn't this always been an intelligence thing? I think across all societies and eras we find that generally a a rather alarmingly large section of population is unable to grasp basic written instructions - and that section usually increases to the majority of people, when we start getting into things like an employment contract, or mortgage document.
Really hard to take your comment serious when the only post on dvt.name is a hello world page, because at least OP is trying to publish and you are lacking moral high ground to judge him thinking LLM writing is good.
Oh if I had a nickle for every web domain I bought and put a hello-world.html into s3 and never checked again ...
FWIW, I'm with GP. It's quite easy to get just mind-numbingly tired reading beyond the first two sentences of a typical LLM output, let alone on something I'm familiar with.
It's on dvt about page in HN, so hardly something hidden. People are different, and in the blog post itself the author writes that in time he became tired of the way LLM wtites
I'm trying to playfully divert away from the captious and unhelpful comment, but if you want to double down, that's ok too. Cheers, my dude, have a good Thursday.
Sure whatever, why even bother commenting if you didn't want to engage then. I don't owe you anything just because you were trying to cheerfully diverge.
Lol my blog was hacked recently and I've been lazy about moving my backed-up mySQL DB to the new WP installation. Not sure where moral high ground enters the picture. If I really wanted to be an asshole, I'd cite a book I co-wrote and another I edited.
> Honestly, I can't fathom thinking that LLM writing is even remotely passable. People that think this should honestly read more.
How do you think the author of the page would read this? That sounded pretty asshole-like for me. If it's not for you I'm really sorry for you, you must have to endure really screwed up people.
Maybe you're right and I was a bit too snarky, apologies to the author if he/she was offended. Writing anything implies some vulnerability, and criticism should be constructive.
I know, and we've all been there. It's comfortable to criticize, only when I had a very divisive publication hit front page that I've seen how hurtful dismissive or sarcastic comments can be (https://news.ycombinator.com/item?id=45277346)
And sorry about your blog :/ didn't know it was hacked. Looking at the comment section of the hello world though it gets pretty obvious LOL. You should consider removing it from your HN about though.
It's kind of interesting how genuinely hard it is to get models to deviate from basically all of these tropes. You can straight up tell it "I hate that card design, do something different, get creative!" and it'll do something either (a) ugly as sin (clearly just essentially a random walk through parameters) or (b) some same-y derivation of that card.
In coding, I've noticed a few tropes as well: everything is a "contract" or an "artifact" (clearly trained on like three decades of Java lol), everything is constantly "backwards-compatible" or "versioned" (even if working on a brand new greenfield project), and a few others.
That's a funny one. I don't use LLMs at all but "load bearing" is such a common/over-used internet joke for DIY building projects and stuff like "load bearing caulk". Have never heard it in a software sense really so am slightly perplexed
> I’m referring specifically to the cards, which exploded in popularity after some YouTuber paid millions for a rare card
Objectively untrue boomer take. Pokemon cards have been popular & have been traded since I was in middle school and I'm 40 now lol. Even without ever collecting them I know how cool having a Holo Charizard was.
If you look at Google Trends you can see that interest in Pokemon Cards was mostly flat until 2021 when Logan Paul made headlines for spending $5m on a card. It spiked again in late 2024 and has remained high when they released an app for trading cards digitally.
Before 2019 they printed fewer than 2 billion cards per year [1]. Since 2021 they are printing 9 billion cards per year, and 12 billion in 2024 since they released the app. And release 7 new sets a year. And they are still selling out as soon as they hit store shelves [2].
The popularity you experienced in grade school is nothing like the revenous demand today. I suspect you might be the one who has fallen behind the times.
> These are not the type of people who you want running a company.
This is quite literally the opposite of reality, and it's funny to see internet experts that haven't so much as raised 100k always criticize seasoned C-level execs. Not that C-levels are geniuses or something (in fact a lot of times they're idiots), but there's a very good reason people are flocking to AI. The downside is relatively minor: a few million wasted, whatever; while the upside could be generational: being on the forefromt of an internet-level technology.
It's easy to make fun of bad ideas in retrospect (the Metaverse, VR, blockchain, etc.) but what people forget is that good ideas are often indistinguishable from bad ideas. So you should (as a tech company; not as a bank or as a hospital) generally prefer a CEO that's willing to swing for the fences rather than someone timid and overly conservative.
The downside is far from minor: seasoned employees are being let go, taking with them the very knowledge and skillsets that built these companies, likely never to return. All for a gamble on new tech that has yet to produce anything resembling worthwhile.
Regarding the Metaverse, VR, blockchain, etc. people were antagonistic towards them at the time, not in retrospect. If anything, people are showing much more hatred towards AI than any of these aforementioned technologies.
I always get downvoted when I say this, but React is imo the biggest piece of astroturfed garbage corpo-slopware in the history of software engineering. It achieved such ubiquitous status for a few reasons:
(1) The extreme boom of software engineering as a "get rich quick" career over the past 15 years, and it being the "default" framework for doing stuff on the web. It's so bad, in fact, that most developers these days don't even really understand the difference between a backend and a front-end. I've had to explain, from first principles, how cookies work. All these very important details are simplified or straight up buried by React and its ecosystem.
(2) The overall groupthink of engineers: a lot of us will weirdly become fixated on some framework, operating system, programming language and turn into absolute zealots. This has a long and storied history (Linux vs Windows, C++ vs Java, and so on, so it's nothing new). React just happened to capture a lot of the zeitgeist even though it was objectively the wrong tool to use for like 90% of use cases.
(3) Terrible alternatives. I mostly blame the W3C for this, as JQuery helpers (selectors, AJAX/websockets, etc.) should've been inducted in the DOM standard much earlier and because the W3C (and by extention, the ECMAscript committee) is essentially a beaureaucratic battleground for big tech[1], it's painfully slow to get anything passed, standards are all over the place, and everyone tries to push their own agenda (Google wants to track you, Facebook wants social stuff, Apple wants secure payments via fingerprints, etc.)
(4) The startup boom of the last 15 years or so. This has always been a bit of a problem, but a common trope has been (and still very much is): if it's good enough for "huge tech company," it's good enough for us. So you've had a ton of startups that have been built from the ground up on React and the sunken cost has always been too much to switch.
{kind=link}
reply